Activity classification by computers has a rich history and this paper seeks to describe, analyze, and compare some methods used in classifying a subset of actions. The creation of temporal templates via motion-energy images (MEI) and motion history images (MHI) were utilized to analyze and quantify frames of videos. Image moments were taken from the MHIs and a learning model was built. The results obtained are compared and discussed along with other comparative methods. The activities focused on were boxing, handclapping, handwaving, running, jogging, and walking.
Interesting Links
- Multiple Activity Videos:
- Handclapping & Boxing Video https://youtu.be/dEtfgAYwCg4
- Multitude activity Video https://youtu.be/x_hFKZzc0jw
Related work in recently published research
There are a number of research publications that are directly related to activity classification, although some of their methods may vary. The most pertinent related work to this project is that of Bobick and Davis [5], in which the idea of using temporal templates to classify activities is discussed. This technique relies primarily on the creation of Motion-energy images and Motion-history images to create a temporal template. Image moments are then extracted from these templates and a distance model is created.
An alternative to temporal templates is suggested in Schuldt, et al [8] in which the use of space-time features are used with a support vector machine classifier. The space-time features are, in essence, points of interest that occur at specific points over time allowing patterns to be developed. They are constructed through the use of image gradients and a Gaussian convolution kernel in which points of interest are located in comparison to a maxima. The use of SVMs in training a model are then taken to achieve fairly good results (and will be compared later herein).
In more recent work, the use of still poses and poselets (body part detection from joint and part positions) [7] to develop an underlying stick figure representation found good results in identifying activities. Additionally, this research took into account the 3D orientation from a trained model. The method achieved results of ~60% correct identification with just the poselet representation and ~65% when the object model was added. Another recent study [3] utilized summary dynamic rgb images and convolution neural network (CNN) to develop a system in which identification was done quickly and reasonably successfully as the researchers were able to get ~89% successful identification.
Methodology and implementation used
Temporal templates were used to create modeled images over a period of time, traditional image moments [9][4][6][2] were then taken and a model was trained.
Temporal Templates
Two types of temporal templates were created: motion-energy images (or binary images) (MEIs) and motion-history images (MHIs). In creating these images, each video frame was taken through a preprocessing step in order to better extract the purposeful, activity related motion from the background and tangential motions within each frame. This was done b first grayscaling each frame, then running the frame through OpenCV Gaussian blurring and morphing functions.
The MEIs were created by taking a temporal diff from each frame and assigning coordinates with a 0 or 1 given if the temporal difference was greater than a constant $\theta$ or not (see examples in figure 1). A $\theta$ of 14 was used throughout the training and testing phases as it was determined to give the best results.






Figure 1: Clockwise, starting in left corner: Boxing, Handwaving, Handclapping, Running, Jogging, Walking
The MHIs were built from those binary images and provide a more nuanced and graded view of the motion over time. These were calculated utilizing hand-crafted constants $\tau$, in which over time gradients were developed. Figure 2 shows an example of different people handwaving as it shows more of the change over time versus the constant that the MEIs show.
In creation of these temporal templates, the $\tau$ constant value for each activity was additionally used (Table 1) a demarcation for how many frames to analyze from a video, so the video sequences (as outlined in the sequences[1]) were divided further into small $\tau$ based chunks. This allowed for consistent training of an activity and expanding the total number of training samples, therefore giving more to the trained model to improve upon prediction.
| Activity | Tau |
|---|---|
| boxing | 7 |
| handclapping | 13 |
| handwaving | 17 |
| jogging | 21 |
| running | 11 |
| walking | 35 |
Table 1





Figure 2: Clockwise, starting in left corner: Boxing, Handwaving, Handclapping, Running, Jogging, Walking
Image Moments
Image moments for each MHI were taken to develop a feature set upon which the temporal templates could be compared. The central ($\mu$) and scale invariant ($\nu$) moments were calculated for the following moments $pq \in {20, 11, 02, 30, 21, 12, 03, 22}$ [4]. The 7 main Hu Moments [6][2] were then calculated from the scale invariant moments. However, after much testing and training, it was determined that the scale invariant moments gave the best results.
Training and Prediction
A large dataset of videos [1] was used as input for training. The K-nearest neighbor algorithm was used to train, classify, and predict the videos. The K-nearest neighbor algorithm works by classifying input based on a plurality vote of nearest neighbors. The features used for training and prediction for this dataset was found to be a combination of the scale invariant features ($\nu$) and the Hu moments. The primary factor here was, in using the Hu moments as features, that enough differentiation was not provided and there was an increase in false positives when testing.
Results and performance statistics
Figure 3: Training results | 90.8% accuracy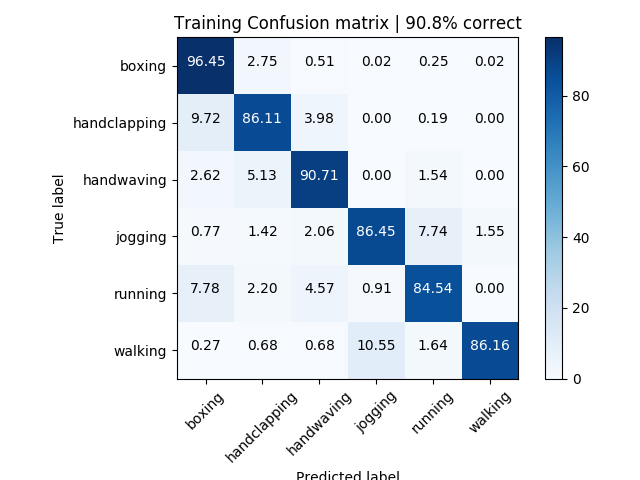
Figure 4: Test results | 84.1% accuracy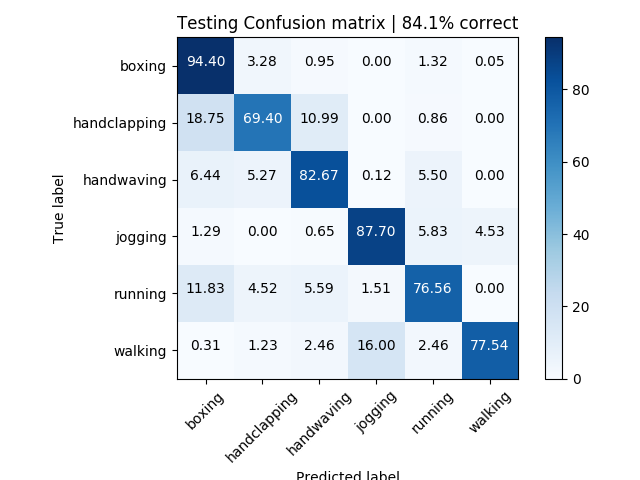
Figures 3 and 4 give a confusion matrix on the overall results from training and testing.
Experiment
In addition to the single activity videos used to train and test against, videos with multiple activities within the same video were run as an experiment (sample frames in Figure 6). The method used for each multiple activity video did the following:
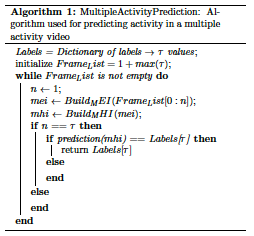
Labels = Dictionary of labels $\rightarrow$ $\tau$ values initialize
$FrameList=1 + max(\tau)$
As outlined in Algorithm [dmap], multiple activity prediction, first gets an initial prediction by building an array of frames. Then as that frame list is iterated over and $mei$ and $mhi$ images are built, when the number of frames is equal to a $\tau$ value, a prediction from the predict engine is created based on the current $mhi$ values and that prediction is compared to the current $\tau$ label. If they are equal, then that label is returned and a $\tau$ number of frames is written and classified with that label.
Analysis of results
The six activities could be further categorized into two primary groups: stationary activities and moving activities. Given this, focus can be placed on results within these categories. The most glaring issue is that of the handclapping results. The trainer most commonly confused it with handwaving and boxing, which does have similar motions.
The moving activities also were difficult to separate, and particularly running and jogging proved to be quite difficult to distinguish between. However, given reasonably differentiated $\tau$ values, the variation was carried through. It could also be argued that the difference between jogging and running may be quite different from person to person, so I still believe that these two classifications are somewhat interchangeable.
Analysis of experiment
As shown in Table 2, the performance times of algorithm used in the experiment was fairly slow. It took close to half a second to complete a full run of the algorithm of frame set analysis and write, which entails running the algorithm (see above) and write the newly labeled frames to video.
| Method | Time (s) |
|---|---|
| Frames (36) analysis and prediction | 0.45s |
| Moments calculation | 0.013s |
| Temporal image creation | 0.15s |
Table 2
The accuracy of the multiple activity videos was hit-or-miss. For example, in the video of just handclapping and boxing, the accuracy was outstanding, showing an above 90% accuracy (see Figure 5). However, in the multitude activity video, accuracy declined. Some of this was due to the definition of jogging versus running, but there were also misclassifications (see Figure 6). Throughout the multiple activity videos, there were misclassifications (see Figure 11), mostly among their two major groups (as discussed above), i.e. walking getting classified as jogging, boxing as handclapping, etc.
Figure 5: Handclapping and Boxing | 90.7% accuracy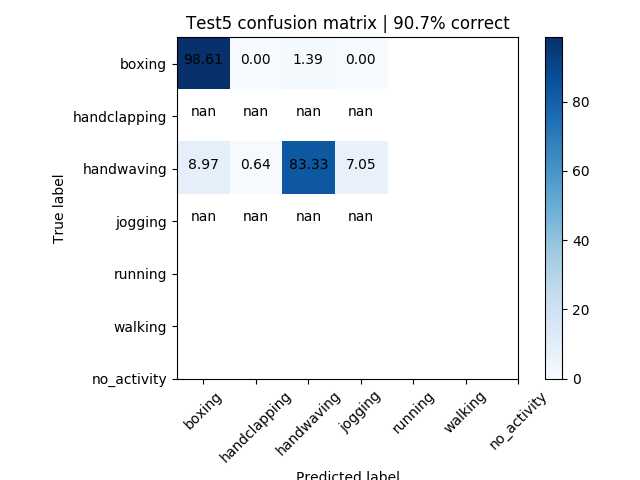
N.B. $nan$ means that label was not expected
Figure 6: Multitude | 36.4% accuracy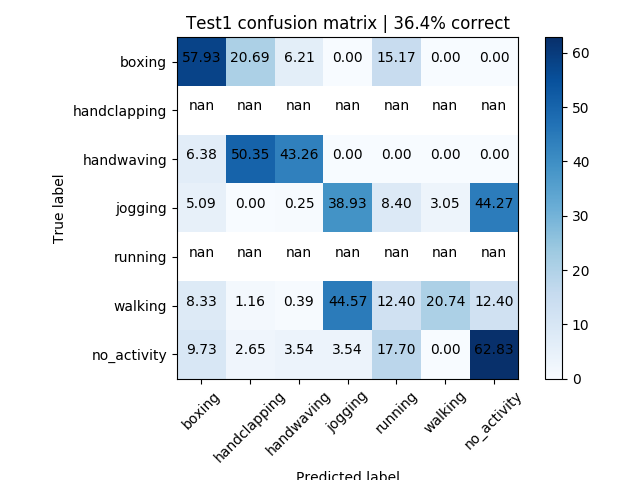
N.B. $nan$ means that label was not expected






Figure 7: Clockwise, starting in left corner: Boxing (correctly identified), Handwaving (incorrectly identified as clapping), Boxing (incorrectly identified as waving), Running (incorrectly identified as jogging), Walking (incorrectly identified as jogging), Handwaving (correctly identified
Analysis of weaknesses
There were some weaknesses that came to light in running these
predictions:
- Currently the method requires differing $\tau$ values or if they are similar, quite different $mhi$ images.
- All the $\tau$ values were carefully set and vetted. Simply not a scalable process.
- As the discussed above, the performance speed is quite slow.
- Still a fairly custom and brittle development process.
Comparison to the state-of-the-art methods
In comparison of the methodology used to the state-of-the-art methods, we can look at the results obtained from usage of an identical dataset from the Schuldt, et al [8]. In comparing the confusion matrices from the Local SVM Approach to this one, the results obtained from the usage of MHI were quite better and more consistently accurate.
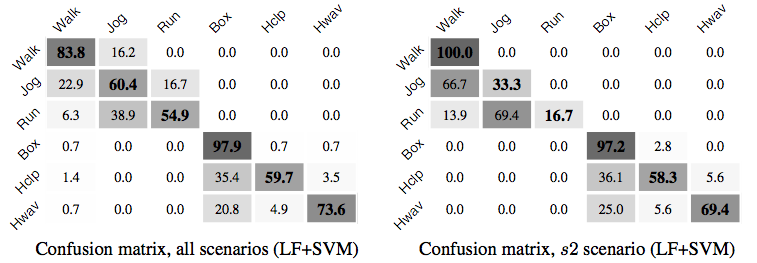
| Method | Accuracy |
|---|---|
| This paper | 84.1% |
| Bilen et al. [3] | 89.1% |
| Zha et al. | 89.6% |
| …others | ~88.0% |
Table 3
Proposals for improvement
There are four proposals for improvement that I believe can improve the performance and success rate of predicting activities:
- Utilizing hidden markov models as a part of the prediction process, particularly in prediction of multiple activities. This would additionally require more training input.
- Using poselets and stick figure representations as used in referenced work [7].
- Building and utilizing convolutional neural networks, similar to the referenced work [3].
- More and variegated training input videos.
References
[1] Action videos. http://www.nada.kth.se/cvap/actions/.
[2] Hu moments | opencv documentation.
[3] H. Bilen, B. Fernando, E. Gavves, A. Vedaldi, and S. Gould. Dynamic image networks for action recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3034-3042, June 2016.
[4] A. F. Bobick. 8D-L2 activity recognition | CS6476 udacity lectures. https://classroom.udacity.com/courses/ud810/lessons/3513198914/concepts/34988000940923.
[5] A. F. Bobick and J. W. Davis. The recognition of human movement using temporal templates. IEEE Transactions on Pattern Analysis and Machine Intelligence, 23(3):257-267, Mar 2001.
[6] Ming-Kuei Hu. Visual pattern recognition by moment invariants. IRE Transactions on Information Theory, 8(2):179-187, February 1962.
[7] S. Maji, L. Bourdev, and J. Malik. Action recognition from a distributed representation of pose and appearance. In CVPR 2011, pages 3177-3184, June 2011.
[8] C. Schuldt, I. Laptev, and B. Caputo. Recognizing human actions: a local svm approach. In Proceedings of the 17th International Conference on Pattern Recognition, 2004. ICPR 2004., volume 3, pages 32-36 Vol.3, Aug 2004.
[9] Wikipedia. Image moments | wikipedia, the free encyclopedia. https://en.wikipedia.org/w/index.php?title=LaTeX&oldid=413720397, 2017. [Online; accessed 2-December-2017].